
One of my Worst GenAI Fears is Inching Closer
My biggest AI fear is here

Here’s a scenario to think about the next time you Google something. Perhaps more accurately, the next time you type a prompt into ChatGPT. It’s a routine query. Something along the lines of “how does gravity work?” ChatGPT, powered by all the water reserves in the world and all the electrical lines that form our interconnected grid, containing all the information ever published, takes a millisecond to produce an entire first year college student’s report on that very question. For most people, that’s good enough. They’ll scroll down to the one or two line summary and move onto the next query, like “why don’t some people believe in gravity?”
Not you, though. Curious and suspicious, you click on the hyperlink behind one claim, leading to an article published on a website dedicated to scientific reporting. Plenty of related articles appear in the sidebar. A human face and a human name appear in the top left corner. A clever logo and publication name adorn the top of the site. Everything appears as it should be and, therefore, the information is trustworthy. Except that on a gut-fueled decision, you decide to run the text through an AI checker that a college professor might use to catch plagiarism. One hundred percent artificial intelligence. A LinkedIn check of the author produces no result.
The information pulled in from ChatGPT came from a website that used ChatGPT to write its own article.
Call this an over exaggeration of what’s happening, but this is the exact scenario that the team behind Kurzgsagt, a scientific YouTube channel with more than 26 million subscribers, ran into when they tested out using more AI products to help in the research process for their videos. And it’s the exact fear I brought up in “Grok’s Information Sewage Pipeline” essay a couple of months ago.
On platforms like Facebook, Instagram, and X, the latter of which is the focus of today’s essay, algorithmic machine learning tools designed to curate information aren’t focused on sending someone outside of the app’s walls. Every search result or tweet displayed is based around what will engage someone enough to keep them scrolling even more, to posting and interacting? Therefore, the information isn’t necessarily the most authoritative or anywhere close to the best sources — it’s the most incendiary.
Our obvious problem is that as our preferred information platforms become more biased, and people use those platforms for even further research, then we get into a position where the information that is supplied to people on major social networks, and is accepted as fact, is coming from poor machine learning sources that are incentivizing the worst kind of information to flow. All of which is certainly not great for a website that wants to position itself as the world’s town hall, but is downright concerning when we add in Musk’s newest obsession for X — artificial intelligence.
Now that we’ve completely democratized distribution, giving anyone with access to a phone or computer the ability to post, the next inevitable disruption is in creation itself. We’re seeing these concerns play out in entertainment media. New apps like OpenAI’s Sora, tools like Google’s Veo3, and experimental spaces like Meta’s Vibes have seen a flood of copyrighted material get remixed, manipulated, and shared faster than anything that happened on YouTube and TikTok. When the only limitation is the right prompt, the funnel for any and all content doesn’t just get larger. It’s infinite.
Apps like Sora are mostly designed for entertainment and social reasons. Sam Altman said as such in a recent conversation with Stratechery’s Ben Thompson. Funny little goofs of your friends palling around with Pikachu right next to videos of Trump ordering a strike on Iran. What could go wrong? But that’s a different topic for a different essay (currently in the works).
New generation encyclopedic search engines like ChatGPT, Grok, Gemini, Llama, and plenty of others aren’t designed to entertain or provide social connection, although the latter is presenting some kind of one-sided relationship formation these days. These engines are designed to collect information and answer questions. Often, these queries come with an expectation of truth, trust, and transparency because people who are using these platforms have come to expect that from Google. Except Google didn’t curate the internet; it condensed it. Misinformation and disinformation spread galore, but there was additional friction.
In this case, friction is a good thing. It prompts a level of thinking and questioning that is completely removed with ChatGPT. For example, why am I clicking on this site? In the question posed above, Google might send me to an official page on NASA explaining gravity. It might send me to Wikipedia, which provides plenty of links through human curation. It might send me to a National Geographic article or, ironically, a Kurzgsagt video — one that is created by humans, and fact checked by humans who have talked to actual experts.
None of this exists with a prompt and answer spit out within seconds. Now, ChatGPT’s use case is not the main issue in this scenario. Again, it’s pulling from the internet, and the internet is open to all. The issue is in how ChatGPT’s answers may be used to then build the next wave of answers chatbots pull in from the internet with each query. Since nothing has actually come for the internet’s dominance in terms of time spent, and therefore in terms of digital ad dollars (a trillion dollar industry), the lack of friction in getting full-fledged answers combined with the zero cost associated with launching a website makes for a pretty quick and risk-free opportunity for the opportunistic entrepreneur. Use ChatGPT to write thousands of articles about a range of topics, create fake journalists, use generative AI video tools to make corresponding videos on YouTube (the world’s second largest search engine), and rake in dollars as these sites play by new GEO, or generative engine optimization, rules.
Voila, the birth of our new self-harming information feedback loop.
THE GOOD AND THE BAD
Diving into this hypothesis means looking at the why and how around new ways to gather information. Tools like ChatGPT help with how. People use a mostly free app to eliminate all friction that comes from Google, which has become far shittier over the last few years as sponsored posts and in-page products push links people are looking for further down the page. This is why Reddit has become the most used appendage in a query, why Microsoft saw an opportunity to come for Google’s search monopoly by revamping Bing with Copilot AI features, and why there was even demand for ChatGPT to begin with when it launched two years ago.
Quite frankly, there is just too much fucking shit on the internet, and trying to figure out what’s good and what’s not, what’s right and what’s wrong is an aggravating task. There you have the why. We’ve all experienced this first-hand. Why wouldn’t most people rely on a one-step process to have the entire internet, all information of all time, shoved through a funnel, producing the most applicable answers within seconds? Not to mention that right now, tools like ChatGPT also don’t feel politicized. It doesn’t read like an opinion. You can see how appealing that is to someone who is getting more and more of their information from social sites like Instagram, TikTok, and X, where the most engaged with news that appears in an algorithmic feed is shared through the veil of an opinion.
Of course, the big question is how many people are actually getting their information from tools like ChatGPT. About one in ten Americans use ChatGPT for news “fairly often,” according to a new report from Pew Research. Another 16 percent “rarely” get news from ChatGPT. This is a far shake from the 55 percent of Americans who often or only get their news from social media sites like X, a previous Pew Research report found.
Far more concerning is how people who use AI chatbots for news find the validity of the news they’re getting. Approximately one third of people who do use chatbots specifically for news found it “difficult to determine what is true and what is not,” per Pew’s report. Not to mention that about half of people who use chatbots for news feel like they often see information that is inaccurate. About 16 percent of people say they often see information that isn’t new, and there’s an additional quarter who couldn’t decipher what’s real and what’s not.
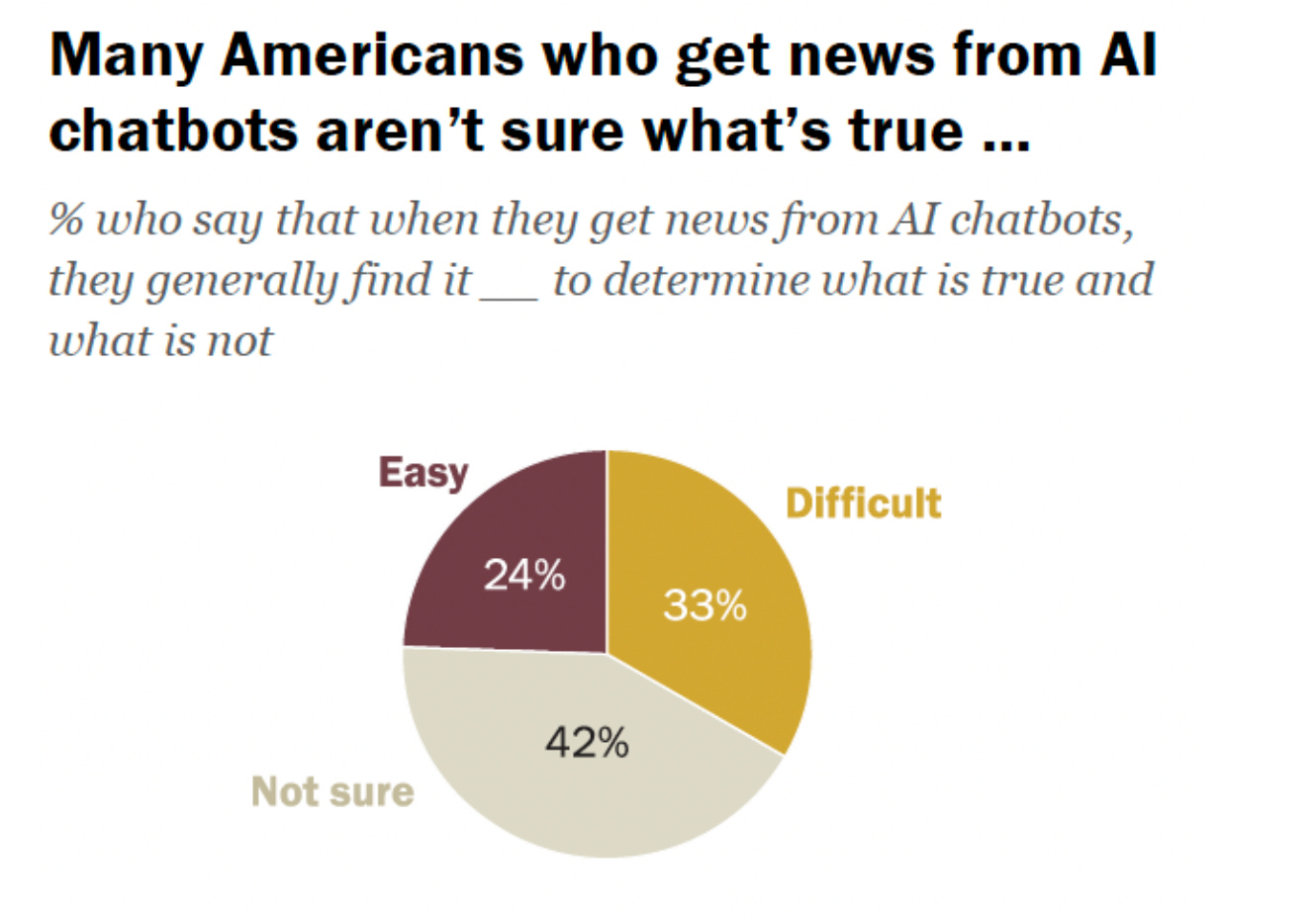
I suppose the one hopeful finding that Pew discovered was that younger AI chatbot users were more likely to assume that information was false, showing how keyed in they are to AI hallucinations. Still, all in all, not exactly inspiring confidence in the future of information sharing for eight billion people on this planet. And the percentage of people who are using these platforms in general for everyday usage — therapy, research, work — means that news will become a bigger part of their diets. In September, ChatGPT recorded 5.9 billion visits, according to SimilarWeb data. That marks the third consecutive month of growth, and is a year over year increase of 89%. It was also the only top 10 website with growth in September versus August engagement.
This tells me two things: people are seeing increased value in the information they are getting, even if they don’t trust it entirely and, more importantly, ChatGPT is getting better at providing the right kind of questions that entrepreneurs can take for their own websites. Again, for websites that ChatGPT will link back too, creating a self-fulfilling prophecy of information self-harm.
The Opportunity
To be clear, this is happening already. There are experts who expect that around 90 percent of all content on the web could be AI generative by the end of this year, according to the Internet Literacy Project. Nine of the fastest growing 100 YouTube channels since July are entirely AI created. Last year, a Wired investigation found that close to half of all Medium posts published within a six-week period were “likely” AI generated. All of these websites, posts, and videos get pulled into answers for queries thrown into Chat GPT and Gemini.
Consider what Google C.E.O., Sundar Pichai, told The Verge’s Nilay Patel when asked about the state of the open web in a new AI-age.
I think part of why people come to Google is to experience that breadth of the web and go in the direction they want to, right? So I view us as giving more context. Yes, there are certain questions that may get answers, but overall… And that’s the pattern we see today, right? And, if anything over the last year, it’s clear to us that the breadth of area we are sending people to is increasing. And so I expect that to be true with AI mode as well.
“The breadth of are we are sending people to is increasing.” Certainly this includes Reddit and other forums that are seeing increases in activity as people seek out tinier internets that appeal to their specific niche interests, but this also means new sources that are popping up and getting clicks. Hence the self-harming information feedback loop. If the websites being clicked on from chatbot tools, creating more authority through engagement and the number of people visiting, are just manipulating the new algorithm, you get an inescapable feedback loop.
WHAT DO WE DO?
When you think about what people coalesce themselves around, the great unifiers of today are getting fewer and fewer. Religion is the obvious one. Sports is another. Music, too. Certainly there are niches within these worlds, but they still create large communities that unify people through a shared clarity. (I wrote about this basic human need being upended last week.) News and information, however, is not a great unifier. There is no Walter Kronkite, no Encyclopedia Britannica. News and information is now the great divider. For-profit companies are incentivized to give people what they want so as to not lose them to the competition. Aggregators therefore pull in information and news that aligns with interests previously discovered once machine learning tools better understand what an individual is interested in. Division ripens.
Enter the opportunists. Those who understand how attention works, how the flow of information works, and how to game the system. They specifically create websites for these platforms to build an audience for their own work, but none of it is real. By the time that advertisers realize that it’s just bots talking to bots, these opportunistic entrepreneurs are onto the next thing. And since OpenAI and other companies are training for engagement first and accuracy second — even if they tell you differently — they’ll pull in and surface these websites that sound exactly like what they’ll produce.
No one can get off the merry-go-round.
What are we supposed to do about it? Information and news are businesses for these companies because they don’t have to be in the business of news or information. They just have to collect it. Regulating what they can and can’t pull from potentially does more harm than good as it very quickly leads to potential censorship on both sides. Approving every outlet or source that applies to be included, kind of like the App Store, may be one option, but it’s a costly endeavor that I can’t see Sam Altman or Mark Zuckerberg including in their budgets.
Three immediate areas stick out to me:
Education: Everything begins and ends with literacy. How do these machines work? How do these websites get pulled in? What are tips that people can keep in mind when double clicking on sources? This should start at the school level but also be tied into the user journey for people using tools like ChatGPT.
Transparency: Which leads to transparency. Like a Rotten Tomato score showing how many critics gave what percentage to a movie to get to the final result, having ChatGPT (and others) show how much of a website is using AI generated content for their own articles could help differentiate between a website that is entirely held up through AI generated copy compared to human curation with help from AI tools.
Ranking: Similar to what Google already does, ranking by authority on subject is crucial to ensuring that the most honest and best information is seen by audiences used to having very little friction in getting an answer. That doesn’t mean it’s always the New York Times. On a topic like NSPM-7, a part of a bill that looks to target specific groups in the United States that could result in suppression of speech for different communities, ChatGPT should link out to reporters like Ken Klippenstein or pull in reporting from Wired. But finding the best authoritative sources on any specific subject instead of just pulling in who has best plugged into GEO standards can help differentiate false information from truth.
This is a conversation that isn’t going to disappear anytime soon. All of the data shows that people using these products increasingly for information and news is only going to increase. Google’s Gemini saw more than one billion visits last month, up 46 percent compared to August, according to Similar Web. Grok is one of the fastest growing chatbots in the United States. ChatGPT now has more than 800 million weekly active users.
This entire system may collapse, but consumer behavior won’t. And that’s what needs to be addressed. If we don’t step in and take it upon ourselves to refocus how information is shared, and how we educate people about what good information is versus bad information, then the very thing required for a democratic republic to function — a trust in information that we seek out and that seeks us out — will disappear. It just will. It’s happened before, and it can happen again.
Walter Cronkite (yes, that was a long time ago!)
What do you all think? Sound off!